
RapidMiner Studio 讓分析者可以毫不費力的從一團亂的資料中設計出可以預測分析跟可調整的資料模型。它的特色及功能簡述如下:
1. 讓您輕鬆的完成預測分析的工作且無需編寫任何程式
忘記那些煩人的程式碼吧!RapidMiner有最棒的最簡的直覺化且視覺化的使用者介面,讓你可以輕鬆的設計分析程序。更棒的是,可以藉由RapidMiner的社群的群眾智慧來給你使用上的最佳建議!
2. 具開放性及可擴展性。
上百種的資料載入、資料轉換、資料模型化及視覺化的方法且可以完整的配合Excel、Access、Oracle、IBM DB2、Netezza, Teradata, MySQL, Postgres, SPSS...等程式及系統讓你輕鬆容易的用你自己的演算法來整合各種資料!
3. 可以對各種規模的資料做現代化的分析,是您大數據分析的最佳選擇!
只要加入 "in-crowd" 並使用in-memory, in-database, in-stream, in-cloud及in-Hadoop來分析各種大小的資料來源。RapidMiner打破了傳統資料分析工具的限制,並讓你可以使用大量的資料來源。
4. 可以在所有重要的平台及作業系統上運行!包括 Windows, Mac OS, 及 Linux
產品特色
|
應用與界面 數據訪問 數據探索 數據準備 |
Modeling 驗證 評分 自動化 |
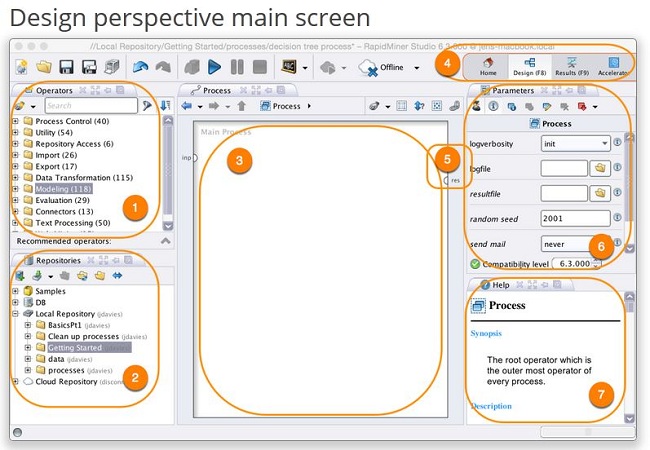
程式截圖
系統需求
Desktop system requirements
When setting up your system, keep in mind that available memory is the most important factor affecting the size of data sets that you can load and analyze in RapidMiner Studio. Additionally, while there is no specific minimal requirement on the CPU, data analysis is a computationally intensive task—the better your hardware, the better your experience. Finally, Java-based RapidMiner Studio is platform-independent and runs on every platform for which an appropriate Java Runtime Environment (JRE) is available.
Minimum
- Dual core
- 2GHz processor
- 4GB RAM
- >1GB free disk space
- Resolution: 1280x1024
Recommended
- Quad core
- 3GHz or faster processor
- 16GB RAM
- >100GB free disk space
Operating System
- Windows 10 (64-bit), Windows 11 (64-bit)
- Linux (64-bit)
- MacOS X 10.13 - 12
Java platform
- 64-bit recommended
- OpenJDK Java 11 JRE (shipped, only needs to be installed manually on Linux)
- Make sure that you are not just installing a headless JRE (as for example Ubuntu does by default)
RapidMiner AI Hub (原為 RapidMiner Server )
Make data science a team sport
Empower people of all skills to collaborate and create AI solutions
- Jumpstart team-based projects, allowing multiple users to work collectively towards a single goal across RapidMiner Studio, Notebooks and RapidMiner Go
- Provide analytics for anyone – RapidMiner Go is included with the AI Hub
- Improve productivity by sharing and re-using connections, data, workflows, code, models and results in a single workspace
- Drive agile, yet governed AI development and easier auditing with fine-grained version control
Turn AI into business impact
Operationalize models and integrate AI anywhere to transform your business
- Instantly put models into production with one-click deployment and carefully manage a governed AI-development lifecycle
- Ensure model resiliency, automatically monitor performance, detect drift and resolve model degradation
- Streamline decision-making through automation of data prep, ETL, modeling, re-training and scoring with job scheduling and process control
- Support decisions in real-time wherever needed with IoT and edge computing capabilities
- Deliver insights to decision-makers and consumers through interactive dashboards, web apps, external applications, popular BI tools and even more with REST or Python APIs
Ensure enterprise-grade security and compliance
Integrate with enterprise regulations, policies and technology
- Enjoy best-in-class identity and access management capabilities
- Set up single sign-on, identity federation or integrate with existing user databases
- Configure granular permissions to authorize and control access to resources
- Complies with modern enterprise authentication, authorization and encryption standards
Deploy, scale and operate with ease
Trust a modern platform architecture that performs reliably
- Deploy the platform wherever you want: in public clouds (AWS, Microsoft Azure or Google Cloud Platform), in a private cloud or on-premises
- Easily install, configure, run and scale the platform on Docker or Kubernetes using pre-built templates
- Spin up ready-to-use VMs from the Microsoft Azure or AWS marketplaces on-demand
- Reduce IT operations burden by having RapidMiner host and manage the platform as a service
- Guarantee platform reliability, resiliency and scalability with high availability configurations, horizontal scale-out strategies and more
系統需求
|
Minimum for RapidMiner Server
|
Operating System
|
RapidMiner Radoop
RapidMiner Radoop provides the first graphical environment for big data analytics, simplifying the
process of creating, executing and operationalizing. Predictive Analytics workflows on Hadoop clusters. Radoop leverages the processing power of Hadoop, enabling analysis on the full breadth and variety of Big Data.
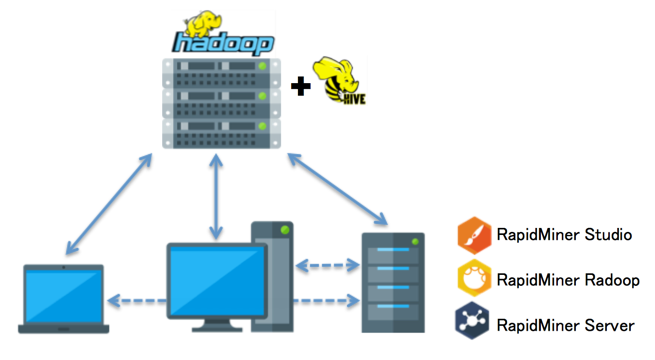
| RapidMiner Radoop通過提供為in-Hadoop執行而實現的複雜運算符,擴展了常見的RapidMiner內存中功能。Radoop包括60多個用於數據轉換的運算符以及以分佈式方式在Hadoop集群上運行的高級和預測建模。 | |
|
|
ETL Capabilities
- Read, store and append from and to Hive tables
- Read CSV (from HDFS, Azure Blob or Datalake, Amazon S3 or local filesystem)
- TEXTFILE, ORC, SEQUENCEFILE, PARQUET and RCFILE formats supported
- Select Attributes, Sample, Filter Examples and Ranges: select a subset of the data according to various criteria and drop non-matching records and attributes Sample
- Generate Attributes, Generate ID, Generate Rank: define new attributes with more than a hundred functions including mathematical and string operations
- Aggregate: calculate aggregate values like averages and counts
- Join: combine multiple data sets based on simple or
- complex keys
- Sort: order data sets according to different attributes
- Normalize: transform numeric values to fix ranges or variances
- Pivot Table: summarize data and change table representation Replace: replace specific values and fix wrong data formats
- Replace: replace specific values and fix wrong data formats
- Replace and Declare Missing Values: handle missing values in various ways
- Remove Duplicates: remove duplicate records that got there by error
- Split Data, multiply: branch the process or partition the data
- Store, Materialize, Append, Union: store and combine data results in Hive or Impala
- Drop, Rename, Copy Table: manage Hive or Impala tables
- Loop and Loop Attributes: organize loops for fixed iterations or over the attributes
- Hive Script and Pig Script: implement custom data transformations in HiveQL or Pig
Modeling
- K-Means clustering
- Principal Component Analysis
- Correlation and Covariance Matrix
- Naive Bayes
- Logistic Regression
- Decision Tree
- Split Validation: evaluate model performance
RapidMiner Studio
Visual workflow designer for the entire analytics team.
| Professional | Enterprise |
|
100,000 Data Rows |
Unlimited Data Rows |
RapidMiner AI Hub (原為 RapidMiner Server )
Connects AI to people, processes and technology. Enterprise-wide collaboration, decision automation, deployment and control, paired with high-powered computation. Includes RapidMiner Go, Notebooks & Real-Time Scoring.
- 64 GB RAM
- 8 Logical Processors
- Unlimited Web Service API Calls
- Real-Time Scoring
- RapidMiner Go
- RapidMiner Notebooks
- Enterprise Support
RapidMiner Radoop
| Radoop Free | Radoop Enterprise |
| Supports 70+ Native Hadoop Operators | Supports 70+ Native Hadoop Operators |
| Community Support | SparkRM Support (All 1500+ RapidMiner Operators) |
| Enterprise Support |