
為學生,教師,學者和您提供專業的文章分析。
使用一個簡單的在線工具即可測量任何英文文章的詞彙和語篇難度。
Text Inspector –由著名的應用語言學教授Stephen Bax創建的基於網絡的語言分析工具。
只需單擊一個按鈕,您就可以從任何給定的文本中獲取有關可讀性,複雜性,詞彙多樣性,估計的CEFL級別以及其他關鍵統計信息的詳細信息。
無論您是計劃課程和材料的ESL老師,努力提高語言技能的ESOL學生,從事研究工作的語言學學生,還是語言專家,Text Inspector 為您提供所需的答案。
由領先的語言學專家創建的屢獲殊榮的工具
Text Inspector由著名的應用語言學教授Stephen Bax創建,並得到了學術合作夥伴The English Language Learning and Assessment研究中心(CRELLA)的支持。利用最新的應用語言學研究成果,我們的工具受到世界各地大學、學院和組織的信任。
為什麼要分析詞彙?
詞彙表是語言的核心組成部分。豐富的詞彙量使口語,聽力,閱讀和寫作的四項核心技能變得更加容易,沒有它,學習者將無法理解語言,表達自己或被理解。
Statistics and readability
Statistics
Sentence Count
This tells you the number of sentences in your text.
You can also check this information by scrolling to the breakdown at the bottom of the page where you’ll find a detailed breakdown.
If the count is wrong, you can change it by clicking on ‘Amend’, changing the count, and then clicking ‘Update scores’ at the top of the page.
Token Count
This tells you the total count of every word (token) in your text (excluding numbers).
For example, the sentence ‘The cat sat on the mat’ contains six tokens.
As before, if this isn’t correct, you can alter this by clicking on ‘Amend’, changing the count, and then clicking ‘Update scores’ at the top of the page.
Type Count
This tells you how many unique words (types) appear in your document, excluding numbers.
For example, the sentence ‘The cat sat on the mat’ contains six words but only five types because the word ‘the’ is repeated.
Click on the ‘Amend’ button and then on ‘Update scores’ at the top of the page if you need to change.
Syllable Count
This tells you how many syllables are within your text.
It does this by referencing data from the Carnegie Mellon dictionary, which includes over 133,000 words with accurate syllable counts. If a word is not available in the dictionary, Text Inspector provides an estimate of the syllable quantity.
However, as syllable counts are closely related to speech, they are heavily influenced by accent, dialect and variety of English and can vary.
Therefore, if you want to change the count, click on ‘Amend’, change the number then click ‘Update scores’ at the top of the page.
Syllable count is used to calculate other statistics such as Flesch Kincaid, so if you change it you will also change those counts.
Type/token Ratio (TTR)
This measures the ratio of the number of different words (types) against the total number of words (tokens). The ratio is the number of types divided by the number of tokens.
Traditionally, this measure has been considered important in evaluating the difficulty of a text.
However, it has recently come under criticism because it is not stable over different lengths of text.
[See the discussion by Peter Robinson in his 2011 paper ‘Second language task complexity, the Cognition Hypothesis, language learning, and performance’.]
For this reason many language analysts prefer to use lexical diversity as a measure.
Average Sentence Length
This counts the average number of words in each sentence to two decimal places.
Number Count
This counts the number of digits in your text.
Words With More than two Syllables/ Percentage
This tells you how many of the words in your text contain more than two syllables and what percentage of the total text this is.
This measure can help indicate how difficult a text is and can be used alongside other measures to determine the complexity of a text.
Average Syllables per Word / Average Syllables per Sentence / Syllables per 100 words
These measures tell you the average number of syllables per word, per sentence and per 100 words.
These measures help indicate the complexity and readability of a text.
Readability Scores
These measures are not reliable for short documents (below 100 words) but can provide excellent insight into longer texts.
Text Inspector uses three popular methods to calculate the readability of a text, using some of the data highlighted above. These are:
→ Flesch Reading Ease
This measure is calculated according to a ratio of total words, sentences and syllables as described here. Easier texts will have higher measures (up to 120) while more difficult texts will score lower (below 40).
→ Flesch-Kincaid Grade
The Flesch-Kincaid grade measure is perhaps the most well-known and used measure of text difficulty and helps determine the reading level of a text.
It considers mainly words, sentences and syllables in a formula which you can see here.
The higher the score given, the easier a text is considered to be.
However, it should be remembered that text difficulty consists of more than just the elements considered by this measure.
→ Gunning Fog index
The Gunning Fog Index is another well-known measure of readability in English and text difficulty.
A score of below 12 suggests a text which could be read widely by the public whereas a score of below 8 indicates a very easy text.
Lexical diversity
What is Lexical Diversity?
As the name suggests, ‘lexical diversity’ is a measurement of how many different lexical words there are in a text.
Lexical words are words such as nouns, adjectives, verbs, and adverbs that convey meaning in a text. They’re the words that you’d expect a child to use when first learning to speak. For example, ‘cat’ ‘play’ and ‘red’.
These are different from grammatical words that hold the text together and show relationships. These words include articles, pronouns, and conjunctions. For example ‘the’, ‘his’ and ‘or’.
What Does Lexical Diversity Show?
Lexical diversity (LD) is considered to be an important indicator of how complex and difficult to read a text is.
To illustrate what we mean, let’s imagine that you have two texts in front of you:
1) The first is a text that keeps repeating the same few words again and again. For example, ‘manager’, ‘thinks’ and ‘finishes’.
2) The second is a text that avoids this kind of repetition and instead uses different vocabulary to convey the same ideas. For example, ‘manager, boss, chief, head, leader’, ‘thinks, deliberates, ponders, reflects’, and ‘finishes, completes, finalises’.
As you can no doubt see yourself, the first text would be much easier to read, whereas the second is likely to be more complex and challenging. You could also say that the second text has more ‘lexical diversity’ than the first.
However, lexical diversity isn’t the only indicator of how complex a text might be or the skill of the language user.
British National Corpus
What is a Corpus?
A corpus (plural= corpora) is a collection of written or spoken texts stored on a computer. These demonstrate exactly how a word or phrase is used in context by real language speakers across a variety of registers.
They are used for many purposes.
- by lexicographers to create dictionaries, grammar reference materials, grammar practice materials and exam practice tests.
- to teachers to help guide the development of tools for the teaching of vocabulary, idioms, phrasal verbs, and collocations (other words that usually occur alongside the chosen word).
- by second language learners who want to understand the authentic use of a word, improve their overall language skills and expand their vocabulary.
- by anyone interested in learning more about language use.
What is the British National Corpus (BNC)?
The British National Corpus (BNC) is a corpus created from over 100 million word samples.
These samples come from a variety of both written and spoken sources including newspapers, fiction, letters, conversations and academic materials.
Written texts account for around 90% of the corpus and spoken texts account for 10%.
Corpus of American English
What is the Corpus of Contemporary American English (COCA)?
The Corpus of Contemporary American English (COCA) is a 1.1 billion word corpus of American English and is one of the most widely used corpora used.
Created by Professor Mark Davis, it contains a well-balanced collection of spoken, fiction, magazines, newspapers, academic texts, TV, movie subtitles, blogs and web pages.
These texts are from the years 1990-2019, with the most recent update taking place in March 2020. This makes it one of the most up-to-date English corpora in the world.
Why use a corpus for English language learning?
Corpora allow you to understand how the English language is used by real speakers, not just presented in textbooks. This is known as a ‘descriptive’ approach to language.
Understanding this authentic language use helps you to improve your understanding of vocabulary and grammar, sound more native in spoken and written communication and use your language skills to the best of your ability.
If you’re an ESOL teacher, using a corpus like COCA or BNC will help guide your language instruction and help you develop better quality course materials.
Why use the COCA and the BNC together?
The COCA tool used in Text Inspector uses the Corpus of Contemporary American English dataset alongside the BNC tool.
Together, they provide a well-rounded, comprehensive research and learning tool that provides great insight into modern English language usage, regardless of which variety of English is being used.
This is because:
- Each corpus offers a different selection of written and spoken texts from different genres and time periods.
- English language use is constantly shaped by global usage. Using both helps to provide a better overall understanding.
Academic Word Lists & Phrases
What is the Academic Word List (AWL)?
The Academic Word List (AWL) is a list of 570 head words (and their connected sublists) that occur frequently in academic texts.
This includes general words such as ‘accumulate’, ‘modify’, ‘precede’ and ‘statistic’.
As these words aren’t connected to any specific subject, they are extremely useful to the ESOL teacher preparing students to learn English at an academic level or the English language learner preparing for further study.
How is the Academic Word List (AWL) structured?
In addition to the 570 head words, the AWL contains ten sublists which are organised according to their frequency. Each of these sublists contains its own group of derived words.
For example, sublist 1 contains the head word ‘assume’. This is followed by its word family which includes:
- assumed
- assumes
- assuming
- assumption
- assumptions
Each of these lists contains 60 words, except the last which contains 30.
English Vocabulary Profile
What is the English Vocabulary Profile?
The English Vocabulary Profile (EVP) is a reference that contains information about which words, phrases, idioms and collocations are used at each level of English learning.
This ground-breaking project was based on collaborative research conducted by two departments of the University of Cambridge, UK: Cambridge University Press and Cambridge English Language Assessment.
It uses the Cambridge Learner Corpus (CLC); a collection of hundreds of thousands of examination scripts from English language learners across the world to help analyse texts in terms of their CEFR level.
By using this tool, ESOL teachers and curriculum creators can understand what aspects of English language are typically learned at each CEFR level and how to develop curricula, course materials and lesson plans with this information in mind.
Scorecard
The Text Inspector Scorecard gives you a clear idea of the level of your text in terms of the CEFR (the Common European Framework of Reference). This is the most widely used reference point in the world for language levels, especially at an academic level.
The analysis includes an ‘at a glance’ Lexical Profile © Score and estimated CEFR level of the text.
It also provides a detailed breakdown of the metrics used in the calculation, including;
- Statistics/Syllables
- Lexical diversity
- Lexical Sophistication: English Vocabulary Profile (incl. % of words at each level)
- Lexical Sophistication: British National Corpus
- Lexical Sophistication: Corpus of Contemporary American English
- Lexical Sophistication: Academic Word List
- Metadiscourse markers
We use these metrics because they are statistically significant when it comes to distinguishing between different levels of language ability.
The greater number of metrics used, the more accurate our analysis is likely to be.
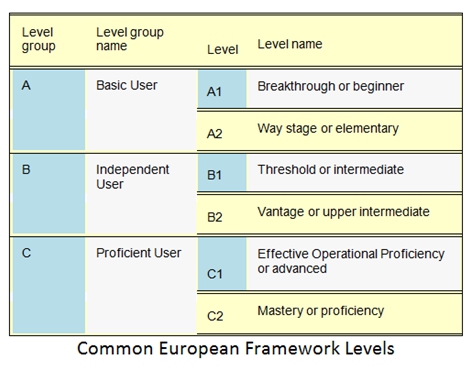
What is the CEFR scale?
The CEFR (Common European Framework of References for Languages) is a framework that helps describe language proficiency in a foreign language using a scale from A1-C2.
This allows:
- language learners to better understand their current abilities and find the right courses and learning materials for them.
- language teachers, curriculum creators and course developers to improve teaching materials and methods.
- educational institutions and prospective employers to directly compare language abilities.
The CEFR levels are as follows:
Parts of Speech Tagger
The Parts of Speech Tagger tool analyses your text and labels each part according to the role it plays in a sentence (its morphological characteristics). This includes nouns, verbs, adjectives and so on.
The tool is based on a modified version of TreeTagger was developed by Helmut Schmid in the TC project at the Institute for Computational Linguistics of the University of Stuttgart.
By using it, you can better understand how a language works and therefore find it easier to teach and learn. If you’re a student of linguistics or involved in linguistics research, the tool can also help in the development and use of corpora
Why use a language tagger tool?
Tagger tools are extremely useful when it comes to both studying and using language.
They analyse the basic grammar of a text and ‘label’ it with the appropriate parts of speech.
By doing this, we can better understand how a particular language works (in our case, English) and therefore improve our learning, teaching and linguistics study of that language.
Importantly, taggers also help distinguish homonyms (words that are spelled the same) which can often pose problems for ESL students and linguists alike.
For example, ‘leaves’ (verb) and ‘leaves’ (noun) are written exactly the same but they are indeed different words with very different meanings.
The POS tagger tool helps solve these problems with just a click of a button.
Metadiscourse markers
What are Metadiscourse Markers?
Text Inspector can analyse an important linguistic feature in a text called ‘metadiscourse markers’.
Also known as ‘transitions’, these are words and phrases such as ‘firstly’ and ‘in conclusion’ that add extra information to a text.
They can:
- show how ideas in a text are connected to each other
- help the reader understand which direction the text is flowing in
- present the writer’s opinion and potentially take a stance
- express the writer’s degree of certainty
- help the writer connect with the audience
Most commonly, these markers are used in academic texts. However, you can also find them other types of texts you’ll encounter over the course of the average day. This can include blog posts, news articles, reviews, newsletters, and even works of fiction.
Why Analyse Textual Metadiscourse Markers?
By studying the textual metadiscourse markers in a text, we can better understand the text and become more effective learners, students and linguists.
This gives us clarity on essential details such as what the author was trying to say, their opinion on the topic, their argument, and the factual content of the text.
Of course when we understand language use more deeply, we can use our knowledge to improve the quality of our own writing.
Adding these types of words can help us express ourselves better in our non-native language, help others to understand what we’ve written, and potentially improve our academic performance.
What Types of Metadiscourse Markers does Text Inspector Analyse?
Text Inspector analyses thirteen categories of metadiscourse marker.
These are as follows:
- Announce Goals (Frame marker)
- Code glosses
- Endophorics
- Hedges
- Logical connectives
- Relational markers
- Attitude markers
- Emphatics (Boosters)
- Evidentials
- Label stages (Frame marker)
- Person markers
- Sequencing (Frame marker)
- Topic shifts (Frame marker)
These categories are based on the types identified by Stephen Bax, Fumiyo Nakatsuhara and Daniel Waller in their 2019 study published in the Science Direct journal. This study was built upon the work done by renowned British linguist Prof. Ken Hyland.
| Free | Standard | Organisation |
| Perfect for occasional users | For frequent users who want to analyse longer texts, use the EVP and download their data. | For organisations of up to 10 people who want to analyse longer texts, download their data and use the EVP. |
|
Word limit Extras Security |
Word limit Extras Security |
Word limit Extras Security |